简介
作为本博客的第一篇机器学习的博文,还是比较老套的谈谈“什么是机器学习”
在回答这个问题之前,不妨看看在使用机器学习算法开发应用程序的流程:
①收集数据
②准备输入数据(可理解为处理数据格式)
③分析输入数据(确保数据集中没有无效数据)
④训练算法
⑤测试算法
⑥使用算法
从上面的简单流程可以看出,机器学习研究的对象是数据,训练算法为基于这些数据产生模型,而使用算法可看做是预测。
我的简单理解就是:通过数据集的处理,构造适合该数据集的模型,基于该模型预测数据的类别。
k-nearest neighbor, K-NN
由Cover和Hart提出;是一种基本分类和回归方法。原理:
假设给定一个训练数据集,其中的实例类别已定;
对于新的实例(不知道类别),将新数据的每个特征值与训练集中对应的特征进行比较;
然后,取前K个最相似的数据,根据其K个最邻近的训练集中的类别,通过投票表决法进行预测。
注:通常K不大于20
不难看出:k近邻法不具有显示的学习过程,而是利用训练数据集对特征向量空间进行划分,并作为其分类的模型。
特点:简单、直观
怎么判定相似
待测数据和训练集中的数据如何比较?
在这里使用的是距离度量,k近邻模型的特征空间一般是n维实数向量空间,使用的距离是欧氏距离。(当然,也可以是其他的距离度量公式)
更一般的有Lp距离:
设特征向量X是n维实数向量空间Rn,xi,xj∈X,xi=(xi(1),xi(2),...,xi(n))T,xj=(xj(1),xj(2),...,xj(n))T
xi,xj的Lp距离定义为
Lp(xi,xj)=(∑nk=1|xi(k)-xj(k)|p)1/p (p≥1)
当p=1时,称为曼哈顿距离;
当p=2时,称为欧氏距离;
而机器学习实战书中所使用的就是欧氏距离。
案例一
根据已有电影的数据和类别,判断未知电影类别: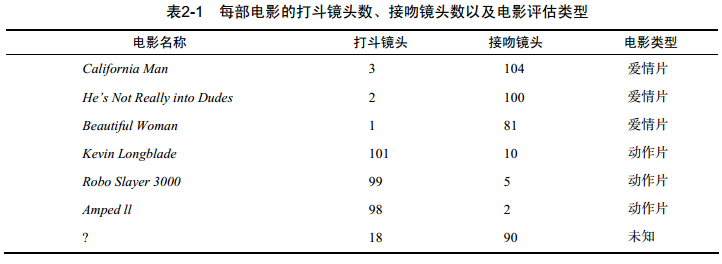
这里数据集刚好,可以看做是:
①点(18,90)到点爱情片(3,104)的距离,计算结果:20.5
②点(18,90)到点爱情片(2,100)的距离,计算结果:18.7
③点(18,90)到点爱情片(1,81)的距离,计算结果:19.2
④点(18,90)到点爱情片(101,10)的距离,计算结果:115.3
⑤点(18,90)到点爱情片(99,5)的距离,计算结果:117.4
⑥点(18,90)到点爱情片(98,2)的距离,计算结果:118.9
排个序:②③①④⑤⑥
假定k=3,取三个最相似的数据,也即是②③①对应的类别为:爱情片
故而判定未知电影是爱情片。
代码实现
Numpy
在机器学习中用到线性代数,是为了简化不同的数据点上执行的相同数学运算。将数据表示为矩阵形式,只需要执行简单的矩阵运算而不需要复杂的循环操作。
而Numpy就是用来处理矩阵数组的库函数。
方法比较多,这里就列出下面用到的一些:
shape函数,查看矩阵或者数组的行数和列数;
案例:import numpy as np a = np.array([[2, 3], [3, 4]]) print(np.shape(a)) # (2, 2) print(type(np.shape(a))) # <class 'tuple'>tile函数,重复某元素,生成指定行数和列数的矩阵
案例:import numpy as np b = np.tile([1, 2], (2, 3)) # 以[1,2]为重复元素,生成2行3列的矩阵 print(b) #[[1 2 1 2 1 2] # [1 2 1 2 1 2]]sum函数,矩阵所有行求和,或者所有列求和,得到一个求和向量
案例:import numpy as np a = np.array([[2, 3, 5], [3, 4, 9]]) print(a.sum(axis=0)) # [ 5 7 14] 列相加 print(a.sum(axis=1)) # [10 16] 行相加 print(a.sum(axis=2)) # Errorargsort函数,返回的是数组值从小到大的排列后,对应的索引值(下标)
案例:
import numpy as np
a = np.array([2, 3, 5, 9, 0, -1])
print(a.argsort()) # 直接从小到大排序
# 输出值 排序情况
# [5 4 0 1 2 3] 对应值:[-1, 0, 2, 3, 5, 9]
b = np.array([[6,0,3],[4,5,6]])
print(b.argsort(axis=0)) # 按列排
# [[1 0 0] 对应值:[[4, 0, 3]
# [0 1 1]] [6, 5, 6]]
print(b.argsort(axis=1)) # 按行排
# [[1 2 0] 对应值:[[0, 3, 6]
# [0 1 2]] [4, 5, 6]]
- 字典排序,可以用lambda函数,也可以用operator
案例:dic = {'a': 1, 'b': 2, 'f': 5, 'd': 1} # dic.items() # [('a', 1), ('b', 2), ('f', 5), ('d', 1)] # 按照键进行升序排列 a = sorted(dic.items(), key=operator.itemgetter(0), reverse=False) # 正序 b = sorted(dic.items(), key=lambda s:s[0], reverse=True) # 反序 print(a, b) # [('a', 1), ('b', 2), ('d', 1), ('f', 5)] [('f', 5), ('d', 1), ('b', 2), ('a', 1)] # 按照键进行降序排列 a = sorted(dic.items(), key=operator.itemgetter(1), reverse=False) # 正序 b = sorted(dic.items(), key=lambda s: s[1], reverse=True) # 反序 print(a, b) # [('a', 1), ('d', 1), ('b', 2), ('f', 5)] [('f', 5), ('b', 2), ('a', 1), ('d', 1)]
不要忘记传入的是dic.items()。而不是dic。
完整代码
import numpy as np
# 创建数据集
def createDataset():
trainSet = np.array([[3,104],[2,100],[1,81],[101,10],[99,5],[98,2]])
# print(trainSet) [[ 3 104]
# [ 2 100]
# [ 1 81]
# [101 10]
# [ 99 5]
# [ 98 2]]
# print(type(trainSet)) # numpy.ndarray
labels = ['爱情片','爱情片','爱情片','动作片','动作片','动作片']
return trainSet, labels
# 计算欧氏距离
def classify(inX, dataSet, labels, k):
"""
:param inX: 待判别的数据
:param dataSet: 已有的归类的数据集
:param labels: 归类数据集的标签
:param k: 最后选几个相似的判断
:return: 判断后的类别
"""
# 将待判别数据生成和数据集一样的维度,方便统一计算;
# 然后和dataSet做差
diffMat = np.tile(inX, (dataSet.shape[0], 1)) - dataSet
# 根据欧氏距离公式,d^2 = (△x)^2 + (△y)^2计算
# 先各个差平方, 即:(△x)^2 和 (△y)^2
sqDiffMat = diffMat ** 2
# 然后在对应每行相加,即(△x)^2+(△y)^2
sqDistances = sqDiffMat.sum(axis=1) # 0为列,1为行 返回结果向量
# 距离的平方开根号,得到距离
distances = sqDistances ** 0.5
# 距离算完了,按照前面的模拟,就需要排序,记录下标
sortedDisIndicies = np.argsort(distances) # distances是一个向量,故而这里不指定列还是行
# 下面就是根据K值,取我们排序后的元素,然后用投票表决法,找出元素个数最多的类别
# 字典,统计个数很方便
classCount = {}
for i in range(k):
voteLabel = labels[sortedDisIndicies[i]]
classCount[voteLabel] = classCount.get(voteLabel, 0) + 1
# 统计完成后,根据字典中值的大小,按照从大到小排序
sortedClassCount = sorted(classCount.items(), key=lambda s:s[1], reverse=True)
# 得到的sortedClassCount的数据格式是:[()]
return sortedClassCount[0][0]
if __name__ == '__main__':
# 创建数据集
trainSet, labels = createDataset()
# 欲判断的数据
test = [18,90]
# K-近邻算法计算
test_class = classify(test, trainSet, labels, 3)
print(test_class) # 爱情片运行后的结果是爱情片,和我们简单手动计算的一致。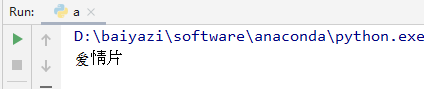
最后,我做了一个PPT,来简单的说明这个问题。把PPT录屏做成了gif的,如下:




