感觉学习
Scrapy之前,应该是爬虫的基础类库。毕竟Scrapy是框架,学习框架之前应该弄熟练基础的类库的使用。
1. 数据来源:
- 大型互联网公司
- 百度指数
- 阿里指数
- 新浪指数
- 政府机构
- 中华人民共和国国家统计局 (http://data.stats.gov.cn/ )
- 世界银行公开数据 (https://data.worldbank.org.cn/ )
- 纳斯达克股票信息 (https://www.nasdaq.com/zh )
- 联合国统计的数据 (https://data.un.org )
- 咨询公司
- 艾瑞咨询
- 麦肯锡
- 第三方数据平台
- 数据堂 (www.datatang.com )
- 贵阳大数据交易所 (trade.gbdex.com )
- 爬虫爬取
2. 爬虫简介
抓取网页数据的程序
做爬虫的语言
PHP、Java、C/C++、Python等
Scrapy框架
高定制型高性能(异步网络框架twisted)、高并发,速度下载很快;
(还有一个爬虫框架:Pyspider 比较简单)
分布式策略 scrapy-reids
主要做:请求指纹去重、请求分配、数据临时存储
爬虫、反爬虫、反反爬虫 之间的斗争
重要的网页数据一般都有反爬虫机制。做爬虫最头疼的不是复杂的页面,而是重要的网站都有反爬虫。
但是,网站做反爬虫,还需要考虑成本问题,不是所有的网站都能做到完备的反爬虫策略。数据价值=机器成本+人力成本
3. 爬虫分类
通用爬虫
搜索引擎用的爬虫系统
目标:尽可能的把互联网上的所有网页下载下来,放到本地服务器,然后做相关处理,最后提供一个检索数据的接口。
爬取流程:
a) 首选选取一部分已有的URL,把这些URL放到待爬取队列。
b) 从队列里取出这些URL,然后解析DNS得到主机IP,然后去这个IP对应的服务器里下载HTML页面,保存到搜索引擎的本地服务器。
之后把这个爬过的URL放入已爬取队列。
c) 分析这些网页内容,找出网页里其他的URL连接,继续执行第二步,直到爬取条件结束。
通用爬虫并不是万物皆可爬,它也需要遵守规则:Robots协议:协议会指明通用爬虫可以爬取网页的权限。Robots.txt 只是一个建议。并不是所有爬虫都遵守,一般只有大型的搜索引擎爬虫才会遵守。
咱们个人写的爬虫,就不管了。
搜索引擎排名:
PageRank值:根据网站的流量(点击量/浏览量/人气)统计,流量越高,网站也越值钱,排名越靠前。- 竞价排名:谁给钱多,谁排名就高。
聚焦爬虫
爬虫程序员写的针对某种内容的爬虫。
4. urllib
在Python2中,是urllib2 ;在 python3.x中被改为urllib.request
看看下面简单的例子:
# Python3.6
#导入库
from urllib.request import *
# 发送url地址,得到响应对象
response = urlopen("http://127.0.0.1:4000")
# read()方法读取文件全部内容
html = response.read()
# 打印源码
print(html)直接使用urlopen打开网页,默认的 User-Agent:"Python-urllib/%s" % __version__
User-Agent: 是爬虫和反爬虫斗争的第一步,养成好习惯,发送请求带User-Agent
我们就需要自己构造一个和浏览器请求很相似的web请求,也就是使用Request。
参数比较多,这里列出部分参数:
- 请求的
url地址 - 请求头
headers,类型是一个字典{} - 请求的方法
method,默认值是None
略微了解HTTP协议的就知道,在请求头中就可以设置请求的各种参数,其中就有我们期望的User-Agent。
Request
下面就简单构造一个Request:
# Python3
#导入库
from urllib.request import *
# 构造Request
request = Request(url="http://127.0.0.1:4000")
# 发送url地址,得到响应对象
response = urlopen(request)
# read()方法读取文件全部内容
html = response.read()
print(html)运行后,发现结果和上一个例子的效果一模一样。
上面也提到了,可以传入请求头,所以我么下面就来实践一下:
打开浏览器,还是以我们前面的网址为例,然后抓包看看它的请求头信息(部分):
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,/;q=0.8
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cache-Control: max-age=0
Connection: keep-alive
Cookie: Hm_lvt_3e7b72d8c528abb722783061a44884f5=1560069575; Hm_lpvt_3e7b72d8c528abb722783061a44884f5=1560512154; scroll-cookie=267|/
Host: 127.0.0.1:4000
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36
却不一定都需要,如Accept-Encoding就不需要,我们做爬虫不需要费劲的将数据下载后,然后还要解压,直接得到数据不是更好。有些可要可不要,如:Host、Accept-Language、Cache-Control、Connection、Upgrade-Insecure-Requests。
而Cookie主要是处理登录的时候的,如果只是爬取静态页面也是不需要的。
User-Agent
爬取静态页面,只要User-Agent就可以了。
# Python3
#导入库
from urllib.request import *
# 构造Request
request = Request(url="http://127.0.0.1:4000", headers={
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36",
})
# 发送url地址,得到响应对象
response = urlopen(request)
# read()方法读取文件全部内容
html = response.read()
print(html)运行结果还是和上面的例子效果一样,可能会有一种无卵用的觉悟。
但是,如果不修改默认的User-Agent,你爬虫的IP是很容易被所爬取的目标网站封掉的。
Response
是服务器响应的类文件,除了支持文件操作的方法外,还支持一些和服务器响应先关的方法。
我们可以在上面的程序中加入:print(dir(response))以查看response所具有的方法。结果如下:
[‘abstractmethods‘, ‘class‘, ‘del‘, ‘delattr‘, ‘dict‘, ‘dir‘, ‘doc‘, ‘enter‘, ‘eq‘, ‘exit‘, ‘format‘, ‘ge‘, ‘getattribute‘, ‘gt‘, ‘hash‘, ‘init‘, ‘init_subclass‘, ‘iter‘, ‘le‘, ‘lt‘, ‘module‘, ‘ne‘, ‘new‘, ‘next‘, ‘reduce‘, ‘reduce_ex‘, ‘repr‘, ‘setattr‘, ‘sizeof‘, ‘str‘, ‘subclasshook‘, ‘_abc_cache’, ‘_abc_negative_cache’, ‘_abc_negative_cache_version’, ‘_abc_registry’, ‘_checkClosed’, ‘_checkReadable’, ‘_checkSeekable’, ‘_checkWritable’, ‘_check_close’, ‘_close_conn’, ‘_get_chunk_left’, ‘_method’, ‘_peek_chunked’, ‘_read1_chunked’, ‘_read_and_discard_trailer’, ‘_read_next_chunk_size’, ‘_read_status’, ‘_readall_chunked’, ‘_readinto_chunked’, ‘_safe_read’, ‘_safe_readinto’, ‘begin’, ‘chunk_left’, ‘chunked’, ‘close’, ‘closed’, ‘code’, ‘debuglevel’, ‘detach’, ‘fileno’, ‘flush’, ‘fp’, ‘getcode’, ‘getheader’, ‘getheaders’, ‘geturl’, ‘headers’, ‘info’, ‘isatty’, ‘isclosed’, ‘length’, ‘msg’, ‘peek’, ‘read’, ‘read1’, ‘readable’, ‘readinto’, ‘readinto1’, ‘readline’, ‘readlines’, ‘reason’, ‘seek’, ‘seekable’, ‘status’, ‘tell’, ‘truncate’, ‘url’, ‘version’, ‘will_close’, ‘writable’, ‘write’, ‘writelines’]
首先,加粗的是私有方法,我们选择readline来测试一下:
print(response.readline)结果:<bound method HTTPResponse.readline of <http.client.HTTPResponse object at 0x0000000002A31828>>
所以我们这里可以在Pycharm中导入Response相关的包,然后追踪一下代码:
在Pycharm中导包:from http.client import HTTPResponse
然后按住Ctrl+单击HTTPResponse,结果如下(选取部分方法):
文件特性
- close
- flush
- isclosed
- read 读完后,直接关闭流,可以用上一个方法测试
- readline 每次读一行,文件没有读完就不会关闭流对象,也可以测试,同上。
响应相关
- getheaders 获取响应头的信息,如:
print(response.getheaders())。
结果是:[('X-Powered-By', 'Hexo'), ('Content-Type', 'text/html'), ('Date', 'Sat, 15 Jun 2019 06:43:17 GMT'), ('Connection', 'close'), ('Transfer-Encoding', 'chunked')] - info 和上一个想过一样,获取响应头的信息,如:
print(response.info())。不同的是,得到的是一个http.client.HTTPMessage消息对象 - getheader(name) 不难理解,获取单个响应头的信息
- geturl 得到当前响应页面的
URL,看URL就可以知道是哪个页面返回的数据,就可以防止重定向问题。 - getcode 得到和
response响应一块发送的HTTP状态码,下面我们看看响应码:
成功200,3是重定向,4服务器页面出错,5服务器本身问题
Get方式数据编码传输
1. URL编码
在请求链接中的汉字,通常都需要进行URL编码。在urllib中使用urlencode函数来解决汉字编码问题。
python2.x:urllib.urlencode({'wd':"测试"})
python3.x:from urllib.parse import urlencode 按照惯例,这里还是追踪一下,可以看见原型中的注解:
def urlencode(query, doseq=False, safe='', encoding=None, errors=None, quote_via=quote_plus):Encode a dict or sequence of two-element tuples into a URL query string.
编码一个字典或者一个两个元素的元组序列到一个URL参数串
以百度搜索为例:
百度关键字搜索的GET形式的URL地址为:https://www.baidu.com/s?wd=urllib.urlencode
后面还有一大堆参数,但是实际上是没有什么用处的,上面的链接就可以搜索关于urllib.urlencode的相关消息。所以下面也利用一下:
先看看编码的代码:
from urllib.parse import urlencode
name = urlencode({'wd':"无涯明月"})
print(name) #wd=%E6%97%A0%E6%B6%AF%E6%98%8E%E6%9C%882. 解码
当然,还有解码,也还是需要提前了解的,使用unquote
python2.x中:urllib.unquote(name)
python3.x中:from urllib.parse import unquote 这里还是追踪一下:
def unquote(string, encoding='utf-8', errors='replace'):默认使用utf-8解码。不妨看看上面编码后的解码:
from urllib.parse import urlencode
name = urlencode({'wd':"无涯明月"})
print(name) #wd=%E6%97%A0%E6%B6%AF%E6%98%8E%E6%9C%88
from urllib.parse import unquote
name = unquote(name)
print(name) #wd=无涯明月这里就给出百度搜索的简单案例:
# Python3
#导入库
from urllib.request import *
from urllib.parse import urlencode
from urllib.parse import unquote
url = "http://www.baidu.com/s?"
keyword = input("请输入您要查询的关键字:")
wd = urlencode({'wd':keyword})
print(wd)
from_url = url + wd
# 构造Request
request = Request(url=from_url, headers={
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36",
})
# 发送url地址,得到响应对象
response = urlopen(request)
page = response.read()
print(page)当然,结果比较尴尬,就是page是字节类型(不妨用type(page)检测),不方便我们查看,下面给出转换成字符串的方法:
page = page.decode(encoding='utf-8')
print(page) #可以搜索一下结果,发现是正确的以百度贴吧为例,我们这里打开百度贴吧,搜索高考,然后点击第二页:
上面的链接我这里放置在这里:http://tieba.baidu.com/f?kw=%E9%AB%98%E8%80%83&ie=utf-8&pn=50
然后,我们点击第三页:
上面的链接我这里放置在这里:http://tieba.baidu.com/f?kw=%E9%AB%98%E8%80%83&ie=utf-8&pn=100
所以,页面链接的变化就是pn的变化:0 - pn=0 1 - pn=50 …
案例代码如下:
# coding:utf-8
# Python3
from urllib.request import *
from urllib.parse import urlencode
from urllib.parse import unquote
def loadPage(url):
"""
根据URL发送请求,获取服务器响应文件
:param url: 需要爬取的URL地址
:return: 爬取的响应内容
"""
request = Request(url, headers={
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36",
})
response = urlopen(request)
page = response.read()
print("正在下载...")
return page
def writePage(page, file_name):
"""
保存爬取的数据到到本地文件中
:param page: 页面数据
:param file_name: 保存的文件的名称
:return: 无
"""
# 由于page是bytes,这里需要转换一下
page = page.decode(encoding='utf-8')
with open(file_name, "w", encoding="utf-8") as f:
f.write(page)
def spider(url, startPage, endPage):
"""
更具url地址,和每一个的特点,计算打开页面的最终的链接
:param url: baseUrl
:param startPage: 起始页
:param endPage: 结束页
:return: 无
"""
start = int(startPage)
end = int(endPage)
for i in range(start, end+1):
pn = (i-1) * 50
full_url = url +"&pn="+ str(pn)
print("开始下载".center(50, "-"))
file_name = "第" + str(i) +"页.html"
page = loadPage(full_url)
writePage(page, file_name)
print("完成下载".center(50, "-"))
if __name__ == '__main__':
kw = input("请输入你要爬取的贴吧:")
startPage = input("请输入起始页:")
endPage = input("请输入结束页:")
url = "http://tieba.baidu.com/f?"
kw = urlencode({'kw':kw})
url += kw
spider(url, startPage, endPage)上面也就是使用GET方式来获取数据的案例,下面看看Post方式的案例。
Post方式数据编码传输
以有道翻译为例,打开网址:http://fanyi.youdao.com/ ,然后我们使用浏览器检查工具对数据包进行抓包,在抓包的时候,为了方便区分资源,可以点击
某个数据包后,用Preview对资源进行查看。其中目标的资源包的Preview的内容如下(以输入无翻译为例):
translateResult: [[{tgt: "There is no", src: "无"}]]
0: [{tgt: "There is no", src: "无"}]
0: {tgt: "There is no", src: "无"}
src: "无"
tgt: "There is no"
type: "zh-CHS2en"可以看见翻译的结果是"There is no",说明数据包找对了。接着开始找他的报文,可以看见Form Data部分,内容如下:
Form Data没有解析前数据
i=%E6%97%A0&from=AUTO&to=AUTO&smartresult=dict&client=fanyideskweb&salt
=15606713929093&sign=0d66e2cc39af99bb091353d8b05baade&ts=156067139290
9&bv=fb2ba7d69650ad4d6ceb3dc46e03624a&doctype=json&version=2.1&keyfrom=f
anyi.web&action=FY_BY_CLICKBUTTION
为了直观,这里点击Form Data 右边的view parsed
解析有的友好格式:(上面的数据也可以看做是下面的字典数据经过URL编码后的数据格式)
i: 无
from: AUTO
to: AUTO
smartresult: dict
client: fanyideskweb
salt: 15606713929093
sign: 0d66e2cc39af99bb091353d8b05baade
ts: 1560671392909
bv: fb2ba7d69650ad4d6ceb3dc46e03624a
doctype: json
version: 2.1
keyfrom: fanyi.web
action: FY_BY_CLICKBUTTION
同理,可以看见请求的URL地址是:
Request URL: http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule很不幸的是,这里用爬虫模拟了一下,然后出现了错误{"errorcode":50}
百度了一下,可以去掉链接中的_o解决。试了一下,可以用。
# coding:utf-8
# Python3
from urllib.request import *
from urllib.parse import urlencode
from urllib.parse import unquote
url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule"
key = input()
data = {
"i": key,
"doctype": "json"
}
data = urlencode(data).encode()
request = Request(url, headers={
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36",
}, data=data)
response = urlopen(request)
print(response.read().decode())测试的结果:
{“type”:”EN2ZH_CN”,”errorCode”:0,”elapsedTime”:0,”translateResult”:[[{“src”:”My name is Tom”,”tgt”:”我的名字是汤姆”}]]}
{“type”:”ZH_CN2EN”,”errorCode”:0,”elapsedTime”:17,”translateResult”:[[{“src”:”你好,今天天气很好。”,”tgt”:”Hello, it’s a fine day today.”}]]}
Cookie
网站服务器为了辨别用户身份和进行Session跟踪,而储存在用户浏览器上的文本文件。
在Cookie中保存了用户名和密码(通常经过RAS加密),故而可以保持登录信息到用户下次与服务器的会话。
比较常见的操作就是在网站服务器端会更具根据Cookie判定注册用户是否已经登录网站。
下面,先登录人人网站,然后我们抓捕数据包,取得登录有的Cookie文件,简单Cookie模拟登录:
from urllib.request import *
headers = {
"Host":"www.renren.com",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36",
# Cookie里记录了用户名,密码(通常经过RAS加密)
"Cookie": "anonymid=jwego3......"
}
request = Request("http://www.renren.com/", headers = headers)
response = urlopen(request)
print(response.read().decode())不妨思考一下,如果每次爬虫都需要手动登录浏览器然后拷贝Cookie下来,还是挺可怕的。在Python中提供了专门的工具来模拟登录,管理Cookie。
在这之前,需要先了解一下我们的urlopen函数,追踪一下可以发现包装的核心代码如下:
https_handler = HTTPSHandler(context=context)
opener = build_opener(https_handler)
opener.open(url, data, timeout)由于urlopen()方法不支持代理、cookie等,所以我们如果要程序管理Cookie就需要使用自己包装的open()函数。
HTTPHandler
先看一个简单的opener()模仿案例:
from urllib.request import *
http_hander = HTTPHandler()
opener = build_opener(http_hander)
response = opener.open("http://www.baidu.com") #当然这里也可以先用Request包装一下
print(response.read().decode())ProxyHandler
代理,很多网站会检测某一段时间异常访问的IP,满足条件会禁止这个IP的访问。
所以我们可以设置一些代理服务器,每隔一段时间换一个代理,就算IP被禁止,依然可以换个IP继续爬取。
下面是一些免费的代理站点:
西刺免费代理IP
快代理免费代理
全网代理IP
89免费代理
from urllib.request import *
proxy_handler = ProxyHandler({"http":"221.229.252.98:9797"})
#nullproxy_handler = urllib2.ProxyHandler({}) 不设置代理
opener = build_opener(proxy_handler)
response = opener.open("http://www.baidu.com")
print(response.read().decode())Done!,下面就开始账户名、密码登录人人案例:
import urllib.parse
import urllib.request
from http import cookiejar
# 通过cookieJar()类构建一个cookieJar()对象,用来保存cookie的值
cookie = cookiejar.CookieJar()
# 通过HTTPCookieProcessor()处理器类构建一个处理器对象,用来处理cookie
# 参数就是构建的CookieJar()对象
cookie_handler = urllib.request.HTTPCookieProcessor(cookie)
# 构建一个自定义的opener
opener = urllib.request.build_opener(cookie_handler)
# 通过自定义opener的addheaders的参数,可以添加HTTP报头参数
opener.addhandlers = [("User-Agent", "Opera/9.80 (Windows NT 6.1; U; zh-cn) Presto/2.9.168 Version/11.50")]
# 人人网的登陆接口
url = "http://www.renren.com/PLogin.do"
# 需要登陆的账户密码
data = {"email": "15128459509", "password": "xxx"}
# 通过URL encode()编码转换
data = urllib.parse.urlencode(data).encode("utf-8")
request = urllib.request.Request(url, data=data)
response = opener.open(request)
print(response.read().decode("utf-8"))当然,这里只是了解,因为在网站中通常都会做JavaScript加密,然后传输数据。
很少有网站会像http://www.renren.com/PLogin.do 一样,直接使用Post方式传送数据。这里只是接触一下,模拟登录还要选择别的技术。
5. Requests
Requests继承了urllib3,连接更加友好。如打开百度:
import requests
response = requests.get("http://www.baidu.com")
print(response.text)其余的不说了,不妨百度。
6. 数据提取
数据提取有多种方式:
- 正则表达式
XPathJsonPathCSS选择器
正则表达式
| 语法 | 说明 |
| 字符 | |
| 一般字符 | 匹配自身。如:a,即匹配a字符 |
| . | 匹配除了"\n"外的任意字符(注意:只是一个字符) |
| \ | 转义字符。如:\.c,即.c;\c,即\c |
| [...] | 字符集,如:[abc]或[a-c],表示abc;如果是[^abc],表示不是abc的其他字符 |
| 预定义字符 | |
| \d | 表示数字,即[0-9] |
| \D | 表示非数字,即[^0-9] |
| \s | 表示空白字符,如空格、回车、换行等 |
| \S | 表示非空白字符,即[^\s] |
| \w | 表示单词字符,即[A-Za-z0-9_] |
| \W | 非单词字符,即[^\w] |
| 数量词 | |
| * | 表示前一个字符0次或者无限次,如abc* |
| + | 表示匹配前一个字符1次或者无限次 |
| ? | 表示匹配前一个字符0次或者一次 |
| {m} | 表示匹配前一个字符m次 |
| {m,n} | 表示匹配前一个字符m至n次 |
| 边界匹配 | |
| ^ | 表示匹配字符串开头,在多行模式中匹配每一行开头 |
| $ | 表示匹配字符串末尾,在多行模式中匹配每一张末尾 |
| \A | 表示仅匹配字符串开头 |
| \Z | 表示仅匹配字符串末尾 |
| \b | 匹配\w和\W之间 |
| \B | 表示[^\b] |
| 逻辑与分组 | |
| | | 表示匹配左右表达式中任意一个,先尝试匹配左边的表达式,一旦匹配成功就跳过匹配右边的表达式 |
| (...) | 被括起来的表达式将被分组,从表达式左边开始每遇到一个分组的左括号'(',编号加一。分组表达式作为一个整体,可以后接数量词, |
正则匹配比较难,一般不怎么用。这里简单介绍介绍一下用法。在Python中,使用正则表达式需要使用re模块。re模块的一般使用步骤如下:
- 使用
compile()函数将正则表达式的字符串形式编译为一个Pattern对象 - 通过
Pattern对象提供的一系列方法对文本进行匹配查找,获得匹配结果,一个Match对象。 - 最后使用
Match对象提供的属性和方法获得信息,根据需要进行其他的操作
Pattern 对象的一些常用方法:
match方法:从起始位置开始查找,一次匹配(而不是所有匹配的结果)。可以自定义查找的起始位置。当匹配成功时,返回一个Match对象,如果没有匹配上,则返回None。## 案例一: import re strs = r'abc123' pattern = re.compile(r'\d+') resu = pattern.match(strs, 3, 5) #下标从0开始,区间为[3, 5) print(resu.group()) #12 #--------------------------------------------------------------- ## 案例二: import re strs = r'Hello Tom Hello Jame' pattern = re.compile(r'([a-z]+) ([a-z]+)', re.I) #re.I表示忽略大小写 resu = pattern.match(strs) # print(resu.group()) #Hello Tomsearch方法:从任何位置开始查找,一次匹配,只要找到了一个匹配的结果就返回,而不是查找所有匹配的结果。当匹配成功时,返回一个Match对象,如果没有匹配上,则返回None。import re strs = r'abc123def456' pattern = re.compile(r'\d+') resu = pattern.search(strs) print(resu.group()) #123 resu = pattern.match(strs) #match匹配是从前到后找,a是非数字,故而匹配失败 print(resu) #Nonefindall方法:全部匹配,返回列表。以列表形式返回全部能匹配的子串,如果没有匹配,则返回一个空列表。## 案例一: import re strs = r'abc123def456' pattern = re.compile(r'\d+') resu = pattern.findall(strs) print(resu) #['123', '456'] #-------------------------------------------------------- ## 案例二: import re strs = r"123.14159 'bigcat' 232312 3.15" pattern = re.compile(r'\d+\.\d*') #*是数量词 resu = pattern.findall(strs) print(resu) #['123.14159', '3.15']finditer方法:全部匹配,返回迭代器。跟findall的行为类似,也是搜索整个字符串,获得所有匹配的结果。但它返回一个顺序访问每一个匹配结果(Match对象)的迭代器。import re strs = r"123.14159 'bigcat' 232312 3.15" pattern = re.compile(r'\d+\.\d*') #*是数量词 resu = pattern.finditer(strs) print(type(resu)) #<class 'callable_iterator'> for i in resu: print(i.group()) # 123.14159 # 3.15split方法:分割字符串,返回列表。按照能够匹配的子串将字符串分割后返回列表import re strs = r"a,b;; c d" pattern = re.compile(r'[\,\;\s]+') #[]是字符集,也就是其中的任意一个 resu = pattern.split(strs) print(type(resu)) # <class 'list'> print(resu # ['a', 'b', 'c', 'd']sub方法:替换,形式如下:sub(repl, string[, count])repl可以是字符串也可以是一个函数,表示用来替换的东西(或规则):repl是字符串,则会使用repl去替换字符串每一个匹配的子串,并返回替换后的字符串。repl是函数,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。count用于指定最多替换次数,不指定时全部替换。## 案例一: import re partten = re.compile(r'(\w+) (\w+)') # \w = [A-Za-z0-9] 按空格分为两组,每一组内容是单词字符(匹配\w) s = 'hello 123, hello 456' resu = partten.sub(r'hello world', s) # 使用 'hello world' 替换 'hello 123' 和 'hello 456' print(resu) # hello world, hello world resu = partten.sub(r'\2 \1', s) # 引用分组,默认前一个分组是\1,后一个是\2,故而这里是交换 print(resu) # 123 hello, 456 hello #-------------------------------------------------------------------- ## 案例二: import re partten = re.compile(r'(\w+) (\w+)') # \w = [A-Za-z0-9] 按空格分为两组,每一组内容是单词字符(匹配\w) s = 'hello 123, hello 456' def func(m): return 'hi' + ' ' + m.group(2) #分组,即分组中的第二个 resu = partten.sub(func, s) # 不指定替换的次数 print(resu) # hi 123, hi 456 resu = partten.sub(func, s, 1) # 最多替换一次 print(resu) # hi 123, hello 456
匹配中文
中文的 unicode 编码范围 主要在 [u4e00-u9fa5],这里说主要是因为这个范围并不完整,比如没有包括全角(中文)标点,不过,在大部分情况下,应该是够用的。
import re
title = u'你好,hello,世界'
pattern = re.compile(r'[\u4e00-\u9fa5]+')
result = pattern.findall(title)
print(result) #['你好', '世界']爬虫中应用正则
如,我们这里想获取http://127.0.0.1:4000 主页(地址也可以是本网站首页:http://baiyazi.top )的文章的标题。浏览器检查一下,然后和标题相关的代码如下:
<h2 class="post-title" itemprop="name headline">
<a class="post-title-link" href="/2019/usehexo-9/" itemprop="url">Hexo官网阅读笔记 | 来必力</a>
</h2>那么正则表达式就可以是:r'<h2 .*>\s+.*</h2>'
可以在一个程序中测试一下,如:
import re
title = r"""
<h2 class="post-title" itemprop="name headline">
<a class="post-title-link" href="/2019/scrapy-8/" itemprop="url">seo-7 | 用Item数据封装</a></h2>
"""
pattern = re.compile(r'<h2 .*>\s+.*</h2>')
result = pattern.findall(title)
print(result) 那么完整的程序如下:
import urllib
from urllib.request import Request,urlopen
import re
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"
}
request = Request(url="http://127.0.0.1:4000", headers=headers)
response = urlopen(request)
page = response.read().decode()
#正则处理,找到发布的每一篇文章的标题
pattern = re.compile(r'<h2 .*>\s+.*</h2>')
resu = pattern.findall(page)
print(len(resu)) # 10
for i in resu:
pattern = re.compile(r"\s{2}") # 有空格,替换多个空格的
print(pattern.sub("", i))结果如下:
10
<h2 class="post-title" itemprop="name headline"><a class="post-title-link" href="/2019/introspection/" itemprop="url">My Reflective Notes</a></h2>
<h2 class="post-title" itemprop="name headline"><a class="post-title-link" href="/2019/usehexo-9/" itemprop="url">Hexo官网阅读笔记 | 来必力</a></h2>
<h2 class="post-title" itemprop="name headline"><a class="post-title-link" href="/2019/scrapy-8/" itemprop="url">seo-7 |用Item数据封装</a></h2>
<h2 class="post-title" itemprop="name headline"><a class="post-title-link" href="/2019/scrapy-7/" itemprop="url">scrapy-7 |Response内置CSS选择器</a></h2>
<h2 class="post-title" itemprop="name headline"><a class="post-title-link" href="/2019/scrapy-6/" itemprop="url">scrapy-6 |Response内置XPath选择器</a></h2>
<h2 class="post-title" itemprop="name headline"><a class="post-title-link" href="/2019/scrapy-5/" itemprop="url">scrapy-5 |Response内置Selector</a></h2>
<h2 class="post-title" itemprop="name headline"><a class="post-title-link" href="/2019/scrapy-4/" itemprop="url">scrapy-4 |Selector提取数据</a></h2>
<h2 class="post-title" itemprop="name headline"><a class="post-title-link" href="/2019/scrapy-3/" itemprop="url">scrapy-3 |Spider开发流程</a></h2>
<h2 class="post-title" itemprop="name headline"><a class="post-title-link" href="/2019/scrapy-2/" itemprop="url">scrapy-2 |第一个爬虫程序</a></h2>
<h2 class="post-title" itemprop="name headline"><a class="post-title-link" href="/2019/scrapy-0/" itemprop="url">scrapy-0 |Python爬虫基础类库</a></h2>XPath选择器
无疑,正则比较不怎么好用。需要比较熟悉正则表达式的规则,还是比较麻烦的。所以有比较简单的XPath来处理xml文档。由于html是特殊的xml文档,故而也可使用XPath。
可以安装:Chrome插件 XPath Helper,比较方便编程。
| 表达式 | 说明 |
| 选取节点 | |
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
| 谓语用来查找某个特定的节点或者包含某个指定的值的节点,被嵌在方括号中。 | |
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()< 3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang=’eng’] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book [price>35.00]/title |
选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00 |
| 通配符 | |
| * | 匹配任何元素节点。 |
| @ | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
| /bookstore/ | 选取 bookstore 元素的所有子元素。 |
| // | 选取文档中的所有元素。 |
| //title[@*] | 选取所有带有属性的 title 元素。 |
| 多选路径 | |
| //book/title | //book/price | 选取 book 元素的所有 title 和 price 元素。 |
| //title | //price | 选取文档中的所有 title 和 price 元素。 |
| /bookstore/book/title | //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
值得注意的是XPath全名是XML Path Language。也就是它是基于xml的一种路径选择语言,在xml文档中查找信息。在运用到Python抓取时要先转换为xml。
故而我们需要先了解如何将一个文本页转换成xml节点树。
lxml解析器
lxml 是 一个HTML/XML的解析器,主要的功能是如何解析和提取 HTML/XML 数据。lxml python 官方文档:http://lxml.de/index.html
下面简单看一个案例:
# 使用 lxml 的 etree 库
from lxml import etree
content = """
<ul><li class="item-0"><a href="link1.html">壹 item</a></li><li class="item-1"><a href="link2.html">贰 item</a></li></ul>
"""
# 利用etree.HTML,将字符串解析为HTML文档, 返回根结点
html = etree.HTML(content)
print(type(html)) # <class 'lxml.etree._Element'>
# 序列化HTML文档,到一个特定编码的字符串
result = etree.tostring(html, encoding="utf-8", pretty_print=True)
# 默认的编码是 ASCII
print(result.decode("utf-8"))结果:
<class 'lxml.etree._Element'>
<html>
<body><ul><li class="item-0"><a href="link1.html">壹 item</a></li><li class="item-1"><a href="link2.html">贰 item</a></li></ul>
</body>
</html>不难看出,大致补全了HTML文档结构。
下面,我们看看xpath是如何使用的,我们这里就来查找一下a标签:
# 使用 lxml 的 etree 库
from lxml import etree
content = """
<ul><li class="item-0"><a href="link1.html">壹 item</a></li><li class="item-1"><a href="link2.html">贰 item</a></li></ul>
"""
# 利用etree.HTML,将字符串解析为HTML文档, 返回根结点
html = etree.HTML(content)
print(type(html)) # <class 'lxml.etree._Element'>
ul_list = html.xpath('//li')
a_list = html.xpath('//a')
for i in ul_list:
print(etree.tostring(i, encoding='utf-8').decode('utf-8'))
# <li class="item-0"><a href="link1.html">壹 item</a></li>
# <li class="item-1"><a href="link2.html">贰 item</a></li>
for i in a_list:
print(i.text)
# 壹 item
# 贰 item
当然,不止是常量字符串,还可以读取HTML文档。所用的方法是:etree.parse(),不妨看看原型:
def parse(source, parser=None, base_url=None): # real signature unknown; restored from __doc__
"""
parse(source, parser=None, base_url=None)
Return an ElementTree object loaded with source elements. If no parser
is provided as second argument, the default parser is used.
The ``source`` can be any of the following:
- a file name/path
- a file object
- a file-like object
- a URL using the HTTP or FTP protocol
To parse from a string, use the ``fromstring()`` function instead.
Note that it is generally faster to parse from a file path or URL
than from an open file object or file-like object. Transparent
decompression from gzip compressed sources is supported (unless
explicitly disabled in libxml2).
The ``base_url`` keyword allows setting a URL for the document
when parsing from a file-like object. This is needed when looking
up external entities (DTD, XInclude, ...) with relative paths.
"""
pass可以放置的资源文件可以是一个文件路径、文件对象、文件链接地址。比较方便。
案例:
from lxml import etree
# 读取外部文件 hello.html
html = etree.parse('./hello.html')
result = etree.tostring(html,encoding="utf-8", pretty_print=True)
print(result.decode("utf-8"))爬虫+使用XPath解析案例
下面一起看看案例,我们下载http://127.0.0.1:4000 即网站主页的图片,检查代码如下:
<img class="site-author-image" itemprop="image" src="/images/avatar.jpg" alt="无涯明月">很容易得出img标签的src地址XPath,可以是//img/@src
import urllib
from urllib.request import Request,urlopen
from lxml import etree
import re
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"
}
request = Request(url="http://127.0.0.1:4000", headers=headers)
response = urlopen(request)
page = response.read().decode()
# 解析html 为 HTML 文档
selector = etree.HTML(page)
links = selector.xpath('//img/@src') # 使用xpath选择器,取出所有img标签,的src。得到列表集
print(type(links)) # <class 'list'>
resu = []
# 正则匹配一下,我不想要fork me on github的图片,只想要本网站的图片
for link in links:
pattern = re.compile(r'/images/.*.[(jpg)(png)]')
resu += pattern.findall(link) # ['/images/avatar.jpg', '/images/beian/beian.png']
# 下载图片
for i in resu:
request = Request(url = "http://127.0.0.1:4000" + i, headers=headers)
response = urlopen(request)
file = response.read()
pattern = re.compile(r'[A-Za-z0-9_]+\.[a-z]{3}')
filename = pattern.search(i).group()
print('开始下载'.center(50, '-'), filename)
with open("d:/" + filename, "wb") as f:
f.write(file)
print('完成下载'.center(50, '-'), filename)
然后,在D盘中就可以看见下载的两种图片。
CSS选择器
和lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据。
官方文档:http://beautifulsoup.readthedocs.io/zh_CN/v4.4.0pip 安装:pip install beautifulsoup4lxml 只会局部遍历,而Beautiful Soup 是基于HTML DOM的,会载入整个文档,解析整个DOM树,因此时间和内存开销都会大很多,所以性能要低于lxml。
| 抓取工具 | 速度 | 使用难度 | 安装难度 |
|---|---|---|---|
| 正则 | 最快 | 困难 | 无(内置) |
| BeautifulSoup | 慢 | 最简单 | 简单 |
| lxml | 快 | 简单 | 一般 |
from bs4 import BeautifulSoup
content = """
<ul><li class="item-0"><a href="link1.html">壹 item</a></li><li class="item-1"><a href="link2.html">贰 item</a></li></ul>
"""
soup = BeautifulSoup(content, features="html.parser")
li = soup.li
print(li) # <li class="item-0"><a href="link1.html">壹 item</a></li>
print(type(li)) # <class 'bs4.element.Tag'>
# 两个属性
print(li.name) # li
print(li.attrs) # {'class': ['item-0']}- 获取标签文本域内容
获取标签内部的文字对象。有三种方式,看看下面简单的例子:
from bs4 import BeautifulSoup
content = """
<ul><li class="item-0"><a href="link1.html">壹 item</a></li><li class="item-1"><a href="link2.html">贰 item</a></li></ul>
"""
soup = BeautifulSoup(content, features="html.parser")
li = soup.li
print(li) # <li class="item-0"><a href="link1.html">壹 item</a></li>
# print(li.next_siblings) # li
# 获取文本节点
print(li.string) # 壹 item
print(li.text) # 壹 item
print(li.get_text()) # 壹 item- find-搜索文档树
from bs4 import BeautifulSoup
content = """
<ul><li class="item-0"><a href="link1.html">壹 item</a></li><li class="item-1"><a href="link2.html">贰 item</a></li></ul>
"""
soup = BeautifulSoup(content, features="html.parser")
print(type(soup)) # <class 'bs4.BeautifulSoup'>
# find 匹配第一个满足的
li = soup.find(name='li') # <li class="item-0"><a href="link1.html">壹 item</a></li>
# find_all 匹配所有,返回列表集
li_list = soup.find_all(name='li') # [<li class="item-0"><a href="link1.html">壹 item</a></li>, <li class="item-1"><a href="link2.html">贰 item</a></li>]
# find_next 在当前标签向后查找给定的标签,匹配第一个
li = soup.find(name='li')
next_li = li.find_next('li') # <li class="item-1"><a href="link2.html">贰 item</a></li>
next_a = li.find_next('a') # <a href="link1.html">壹 item</a>
# find_all_next 在当前标签向后查找给定的标签,匹配所有
ul = soup.ul
a_list = ul.find_all_next('a') # [<a href="link1.html">壹 item</a>, <a href="link2.html">贰 item</a>]
# find_previous 在当前标签向前查找给定的标签,匹配首个
last_a = a_list[1] # <a href="link2.html">贰 item</a>
li = last_a.find_previous('li') # <li class="item-1"><a href="link2.html">贰 item</a></li>
a = last_a.find_previous('a') # <a href="link1.html">壹 item</a>
# find_all_previous 在当前标签向前查找给定的标签,匹配所有
li_list = last_a.find_all_previous('li') # [<li class="item-1"><a href="link2.html">贰 item</a></li>, <li class="item-0"><a href="link1.html">壹 item</a></li>]
a_list = last_a.find_all_previous('a') # [<a href="link1.html">壹 item</a>]
# find_parent name默认None,返回直接父辈元素。写name可以是上上级,就返回上上级父元素标签
li = last_a.find_parent() # 直接父元素 <li class="item-1"><a href="link2.html">贰 item</a></li>
ul = last_a.find_parent('ul') # 指定父元素 <ul><li class="item-0"><a href="link1.html">壹 item</a></li><li class="item-1"><a href="link2.html">贰 item</a></li></ul>
# find_parents
parents = last_a.find_parents() # 直接父元素 和上层所有父辈元素
# [<li class="item-1"><a href="link2.html">贰 item</a></li>, <ul><li class="item-0"><a href="link1.html">壹 item</a></li><li class="item-1"><a href="link2.html">贰 item</a></li></ul>,
# <ul><li class="item-0"><a href="link1.html">壹 item</a></li><li class="item-1"><a href="link2.html">贰 item</a></li></ul>,
# ]
# 下面四个方法是兄弟元素的相关方法,不演示了。
# 'find_next_sibling', 'find_next_siblings'
# 'find_previous_sibling', 'find_previous_siblings',select方法-按照CSS选择器查找
不妨看一个简单的案例:
from bs4 import BeautifulSoup
body = """
<ul>
<li class='s'>1 2 3</li>
<li id='t'>one two three</li>
<li>壹 贰 叁</li>
<li>一 二 三</li>
</ul>
"""
soup = BeautifulSoup(body, features='html.parser')
# 标签选择器,直接使用名字
print(soup.select('ul')) # [<ul>...</ul>]
# 类选择器
print(soup.select('ul li.s')) # [<li class="s">1 2 3</li>]
# id选择器
print(soup.select('li#t')) # [<li id="t">one two three</li>]
# 子元素选择器 >
print(soup.select('ul > li')) # [<li class="s">1 2 3</li>, <li id="t">one two three</li>, <li>壹 贰 叁</li>, <li>一 二 三</li>]不妨看看本网站关于CSS选择器的教程
按照属性查找
当然,标签中可能有其他的属性,我们可以按照属性查找:
from bs4 import BeautifulSoup
body = """
<input type="text" name="user"/>
<input type="email" name="em"/>
<input type="password" name="ps"/>
"""
# 使用字符串常量,创建 Beautiful Soup 对象
soup = BeautifulSoup(body, features='html.parser')
# 使用本地HTML文件,创建对象 Beautiful Soup 对象
# soup = BeautifulSoup(open('index.html'))
# 格式化输出 soup 对象的内容
# print soup.prettify()
print(soup.select('input[type="password"]')) # [<input name="ps" type="password"/>]
# soup.select('p a[href="http://example.com/elsie"]')获取标签文本内容
from bs4 import BeautifulSoup
body = """
<span class="w"><b>挡泥</b></span>
<span id="r">老路</span>
"""
soup = BeautifulSoup(body, features='html.parser')
resu = soup.select('span')
print(type(resu[0])) # <class 'bs4.element.Tag'>
# bs4.element.Tag.get_text() # Get all child strings, concatenated using the given separator.
print(resu[0].get_text()) # 挡泥
# 获取文本节点三种方式都可以:
# resu[0].string
# resu[0].text
# resu[0].get_text() JSON
和xml的地位不相上下,很厉害。Json在线解析网站:http://www.json.cn/#json简单说就是javascript中的对象和数组,所以这两种结构就是对象和数组两种结构,通过这两种结构可以表示各种复杂的结构json模块提供了四个功能:dumps、dump、loads、load,用于字符串 和 python数据类型间进行转换。
loadsJson格式字符串解码转换成Python对象
- JSON object ==> Python dict
- JSON array ==> Python list
- JSON string ==> Python unicode
- JSON number(int) ==> Python int,long
- JSON number(real) ==> Python float
- JSON true ==> Python True
- JSON false ==> Python False
- JSON null ==> Python None
案例:
import json
jstr = '{"city": "北京", "name": "大猫"}'
print(type(json.loads(jstr))) # <class 'dict'>
print(json.loads(jstr)) # {'city': '北京', 'name': '大猫'}dumps
把一个Python对象编码转换成Json字符串,返回一个str对象。
转换的规则,刚好和上面的相反。
import json
jstr = {"city": "北京", "name": "大猫"}
print(type(json.dumps(jstr))) # <class 'str'>
print(json.dumps(jstr)) # {"city": "\u5317\u4eac", "name": "\u5927\u732b"}
# json.dumps() 序列化时默认使用的ascii编码
# 添加参数 ensure_ascii=False 禁用ascii编码,按utf-8编码
print(type(json.dumps(jstr, ensure_ascii=False))) # <class 'str'>
print(json.dumps(jstr, ensure_ascii=False)) # {"city": "北京", "name": "大猫"}另外的dump、load就不介绍了,是操作文件的。下面就介绍解析JSON文件的JsonPath
JsonPath
JsonPath 是一种信息抽取类库,是从JSON文档中抽取指定信息的工具,提供多种语言实现版本,包括:Javascript, Python, PHP 和 Java。
下载地址:https://pypi.python.org/pypi/jsonpath
安装方法:点击Download URL链接下载jsonpath,解压之后执行python setup.py install
官方文档:http://goessner.net/articles/JsonPath
由于我使用的是Pycharm工具,比较方便,直接设置中安装就可以了。JsonPath与XPath语法对比:
| XPath | JSONPath | 描述 |
|---|---|---|
/ | $ | 根节点 |
. | @ | 现行节点 |
/ | .or[] | 取子节点 |
.. | n/a | 取父节点,Jsonpath未支持 |
// | .. | 就是不管位置,选择所有符合条件的条件 |
\* | \* | 匹配所有元素节点 |
@ | n/a | 根据属性访问,Json不支持,因为Json是个Key-value递归结构,不需要。 |
[] | [] | 迭代器标示(可以在里边做简单的迭代操作,如数组下标,根据内容选值等) |
| | | [,] | 支持迭代器中做多选。 |
[] | ?() | 支持过滤操作. |
| n/a | () | 支持表达式计算 |
() | n/a | 分组,JsonPath不支持 |
使用
以http://www.lagou.com/lbs/getAllCitySearchLabels.json 为例。
import urllib
from urllib.request import Request,urlopen
import jsonpath
import json
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"
}
request = Request(url="http://www.lagou.com/lbs/getAllCitySearchLabels.json", headers=headers)
response = urlopen(request)
page = response.read().decode()
# print(page)
# 把json格式字符串转换成python对象
jsonobj = json.loads(page)
# 从根节点开始,匹配name节点
resu = jsonpath.jsonpath(jsonobj, '$..name')
print(resu)
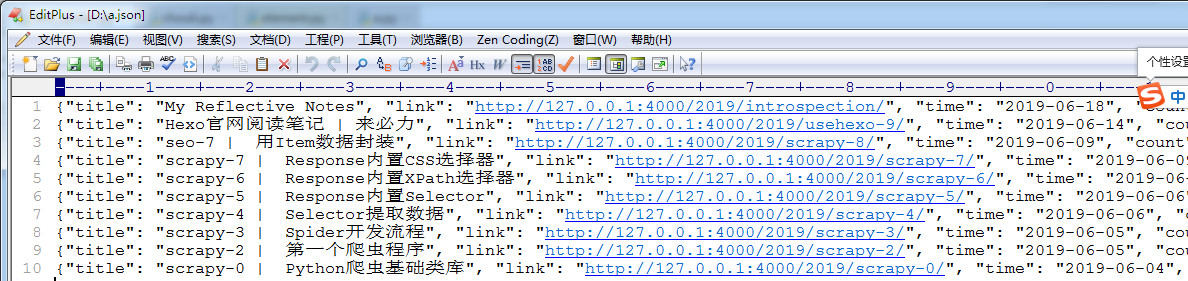
案例:爬取主页中的内容
要求:
- 使用requests获取页面信息,用XPath / re 做数据提取
- 获取每个帖子里的标题、标题链接、发文日期、字数统计、缩略内容
- 保存到 json 文件内
import urllib
from urllib.request import Request,urlopen
import json
from lxml import etree
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"
}
request = Request(url="http://127.0.0.1:4000", headers=headers)
response = urlopen(request)
page = response.read().decode('utf-8')
html = etree.HTML(text=page)
articles = html.xpath('//*[@id="posts"]/article')
# for i in articles:
# print(etree.tostring(i, encoding='utf-8').decode('utf-8'))
for article in articles:
title = article.xpath('.//div/header/h2/a/text()')[0]
link = "http://127.0.0.1:4000" + article.xpath('.//div/header/h2/a/@href')[0]
# 标题、标题链接、发文日期、字数统计、缩略内容
time = article.xpath('.//div/header/div/span[1]/time/text()')[0].strip()
count = article.xpath('.//div/header/div/div/span[3]/text()')[0].strip()
content = article.xpath('.//div/div[1]/text()')[8].strip()[0:-14]
file_content = {
"title":title,
"link":link,
"time":time,
"count":count,
"content":content
}
print(count)
# 转换字典成为json字符串
# print(json.dumps(file_content,ensure_ascii=False).encode('utf-8').decode('utf-8'))
with open("d:/a.json", 'a') as f:
f.write(json.dumps(file_content,ensure_ascii=False) + "\n")结果截图: